Overview
Modernized a 2023 Master's research project into a production-ready ML system for detecting sexist language. Restructured from Jupyter notebooks into a scalable FastAPI application with Docker deployment, comprehensive testing, and interactive web interface.
Interface
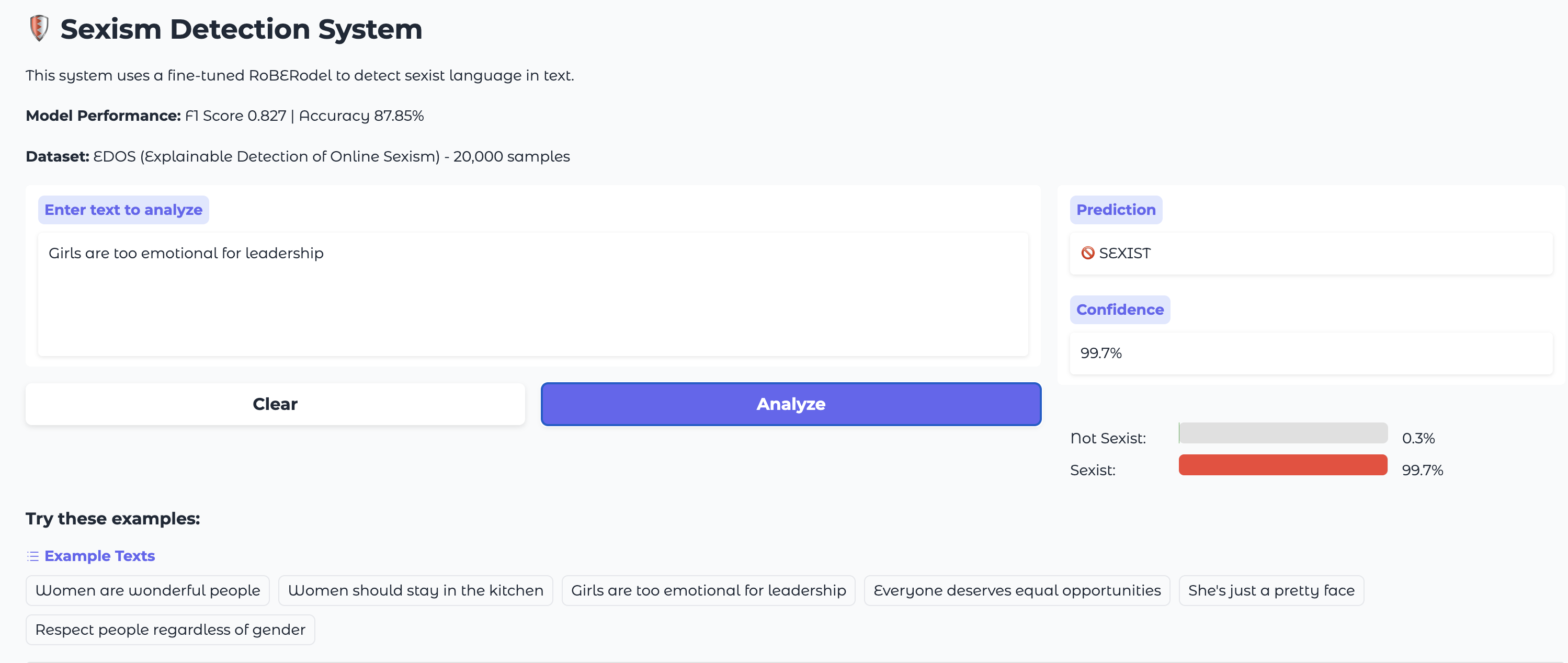
Interactive Gradio interface with real-time predictions and confidence visualization
Key Achievements
- • F1 Score: 0.827
- • Accuracy: 87.85%
- • Binary classification (sexist/not sexist)
- • 20,000 EDOS dataset samples
- • FastAPI with OpenAPI docs
- • 80-95ms inference latency
- • Batch processing (up to 100 texts)
- • Request validation & error handling
- • Docker & docker-compose setup
- • Gradio web interface
- • Health monitoring
- • Multi-container orchestration
- • Modern Python package structure
- • Type hints & modular design
- • Comprehensive testing
- • Clean Git history (12 commits)
Technical Implementation
Training Strategy
Trained on Google Colab (Tesla T4 GPU) to overcome local hardware limitations, reducing training time from 4-6 hours (Mac M3) to 90 minutes while achieving target performance metrics.
Architecture
RoBERTa-base encoder with custom classification head, optimized preprocessing pipeline with LRU caching, and PyTorch DataLoaders for efficient batch processing.
Deployment
Multi-container setup with separate API and UI services, automatic model loading on startup, error handling with proper HTTP status codes, and CORS middleware for cross-origin requests.
Key Trade-offs & Design Decisions
Binary vs. Multi-class
Focused on binary classification (sexist/not sexist) rather than fine-grained categories (threat, derogation, animosity, prejudiced) to maximize F1 score and deployment simplicity. Binary classification is more actionable for content moderation.
Model Size
Used RoBERTa-base (125M parameters) instead of RoBERTa-large (355M parameters) to balance performance with inference speed and deployment costs. Achieved comparable results (F1 0.827 vs. 0.83) with 3x faster inference.
Training Infrastructure
Opted for cloud GPU (Colab) over local training to avoid 4-6 hour Mac M3 training time and system freeze issues. Demonstrates practical problem-solving and resource optimization.